
はじめまして!hacomono インターン生の、インフラとウマと馬が大好きなかわにーと申します。お馬さんかわいい。
2022年6月に入社してから2年弱経ち、このタイミングでやってきたことの整理として振り返り記事を書いています。
hacomono のインターンに興味を持っていただける方の参考となれば幸いです。
(※編集部注:2024年1月現在、hacomono開発チームのインターンは募集停止しております。再開次第、hacomonoプロダクト公式Xなどでお知らせいたします!)
hacomono に応募したきっかけ
大学に入学してから今まで、気の赴くままに趣味として低レイヤやインフラ技術を学んでいました。何か役に立つようなプロダクトを作るわけでもなく、ただ自分の好奇心に従って。
しかし、大学院修士1年の頃、早期選考、インターン….、就活早期化の波が押し寄せます。
趣味ばかりで実務経験のない私は、つよつよ学生エンジニアが跋扈する就活戦争で戦っていけるのだろうかと思い、少しでも経験を積もうと考え、Wantedly でインターンを探していました。
できれば自分の好きな分野を伸ばしたく、インフラ、なんならクラウドを触れるインターンはないだろうかと探していたところ、この募集を見つけました(現在は終了しています)。
パブリッククラウドを扱えて、IaC も実運用環境でできる!最高じゃないか!ということで早速応募し、今に至ります。
hacomonoでやってきたこと
入社から今までの2年弱でやってきたことは、順に
- 監視基盤のマネージド & IaC 化
- 勤怠打刻 CLI アプリの作成
- git-flow を GitHub Actions で制御
- BigQuery のクエリ作成
- PRごとの検証環境作成 ( playground )
- Istio を使った Service Mesh の検証
になります。
改めて並べてみると、幅広い経験をさせてもらってますね…。
この中で特に印象深かった、
1. 監視基盤のマネージド & IaC 化
5. PRごとの検証環境作成
を振り返りたいと思います。
監視基盤のマネージド & IaC化
hacomono に入社して初めて割り振られたタスクがこれです。
当時の hacomono では、お客様の環境ごとに個別の環境を立ち上げるシングルテナントが大多数を占めていました。膨大な環境を一括で監視するために、Grafana と Prometheus を使い CPU、メモリ使用率や、Nginx 関連のメトリクスを取得していました。
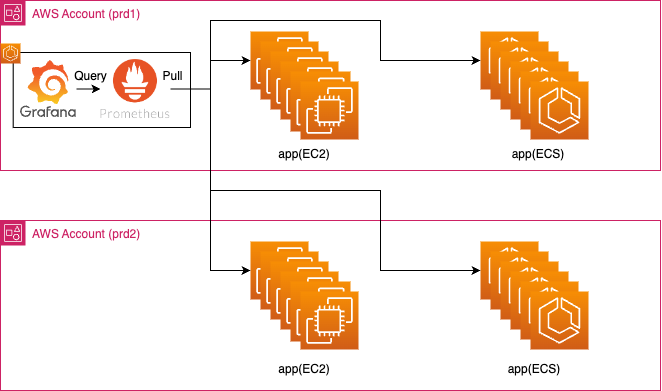
しかし、Grafana & Prometheusを 単一の ECS クラスタ上で動作させていたため、クエリ操作とPull操作を1つのコンテナで行わなければならず、高い負荷が掛かります。
それによりダッシュボードを開くだけでも時間が掛かってしまい、利便性を損ねていました。
また、Prometheus が取得したメトリクスはすべてローカルに書き込まれていたため、データが吹き飛ぶリスクもあります(EFSがマウントされていたのでよっぽど大丈夫だとは思いますが)。
これを解消するため、Prometheus & Grafana のマネージド化を行いました。
Amazon Managed Service for Prometheus(AMP)は メトリクスの保存先を提供するマネージドサービスです。あくまでも保存先であって、AMPはメトリクスの収集を行わないため、メトリクスを書き込む Agent を用意する必要があります。
AMP はメトリクスを 150日間保存してくれるほか、書き込みが多くなった場合は自動でスケールしてくれます。
Amazon Managed Service for Grafana(AMG) は Grafana のマネージドサービスで、インフラを全く意識することなく通常の Grafana と同じように使うことができます。
Cloud Watch 等もデータソースに選ぶこともでき、1つのダッシュボードにまとめられます。
ここまでを踏まえ、下記のシステムを構築しました。
- Prometheus Agent が、Service Discovery を使って検知した App のメトリクスを取得
- 取得したメトリクスは一時的に Prometheus Agent に保存され、順に AMP に書き込まれる
- AMG は ダッシュボードが開かれると、AMP に対しクエリを発行し、メトリクスの可視化を行う
※ Cloud Watch に関しては、AMG から直接アクセスされます。
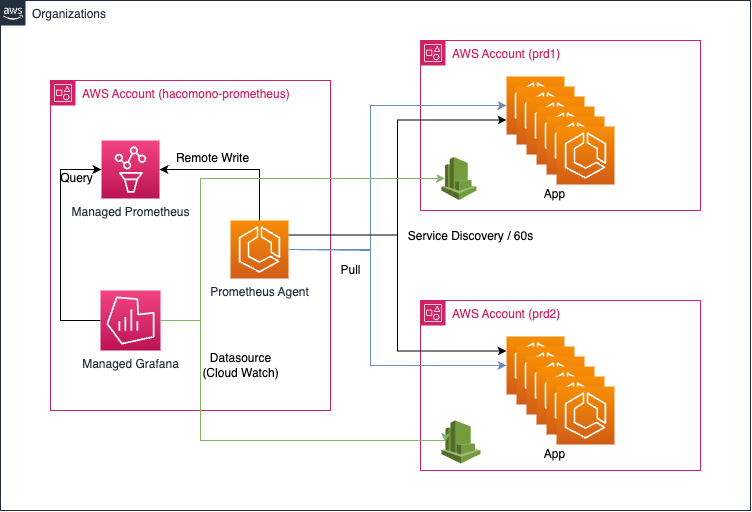
この環境を Terraform を使って構築しました。
Terraform も AWS も初めての経験だったため、苦労しながらもなんとか構築することができました。
ここで得た知識(特に IAM 周り)が、今のベースになっています。
PRごとの検証環境作成
2023年の頭くらいに担当したタスクです。
hacomono では、特定 PR を検証するためには、社内で既に立ち上がっている環境にブランチを手動で当てる必要がありました。
ローカルで1人で開発する場合は問題ありませんが、PdM や QA、デザイナーの方々が先行環境を気軽に触ることができず、手間になります。
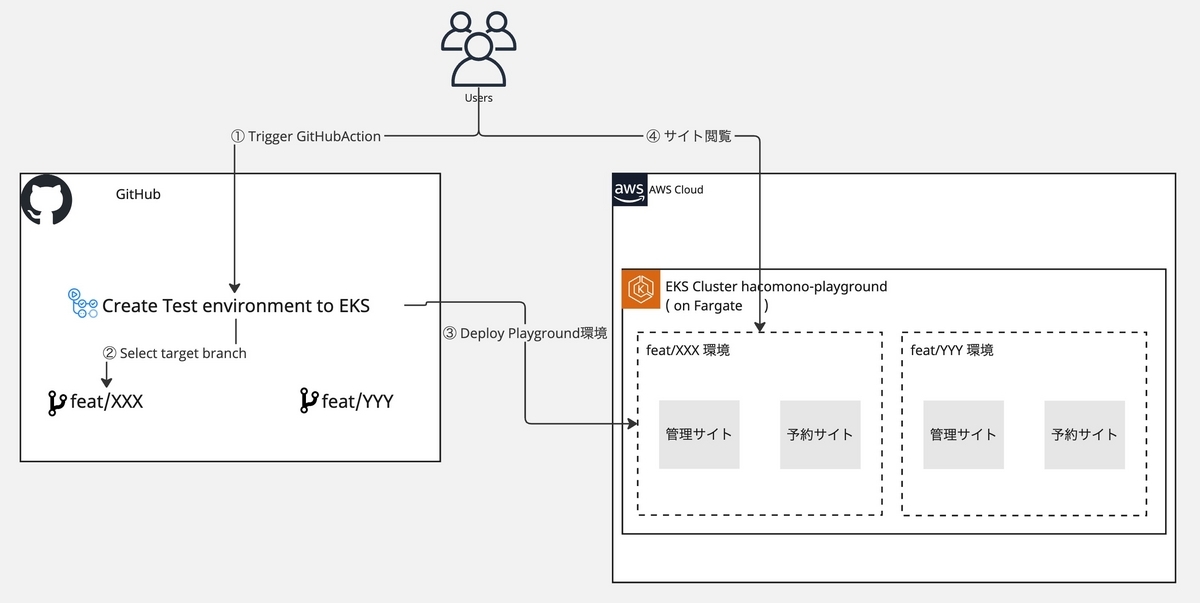
そこで、EKS (on Fargate) を使い、PR ごとの検証環境を気軽に立ち上げられるシステムを構築しました。
- PR を作成した Branch を指定し、GitHub Actions の workflow を起動
- workflow が Docker イメージの Build を行い、ECR に Push する
- workflow が EKS に対し、テンプレートに環境独自の情報を付加した K8s manifest を Apply する
- PR のコメントに URL が通知されるので、利用者はそれにアクセスする
これで検証環境自体は気軽に立てられるようになったのですが、社内には人的リソース含め K8s の保守に割けるリソースがあまりなく、クラスタやアドオンのアップデートが大きな負担になっています。
システムの設計時、Code Deploy や ECS、EKS 等様々な方法を検討しましたが、保守性がきちんと詰められていませんでした。
失敗からの教訓にはなりますが、インターンを通じてシステム設計において考慮すべきことを身をもって体感できたと思います。
本番環境でないからこそ、インターンだからこそできる失敗でした。(社員の皆さん本当にありがとうございます)
現在は別の検証環境との繋ぎこみを行っている関係で、システムを丸ごと変更するのは難しくなってしまいましたが、少しでも運用負担を下げるためにドキュメントの整備や、自動化できるところは自動化していきたいと考えています。
おわりに
長くなりましたが、ここまでお読みいただきありがとうございました。
hacomono は今までの経験関係なく、様々なタスクを任せていただける環境です。
またとにかく物腰の柔らかい優しい方が多く、気持ちよく働くことができます。
私は、入社当初ベンチャーはイケイケでなければならないと恐れ慄いていましたが、いい意味でイメージが変わりました。
私は4月でインターンを離れ、別の企業に就職する予定ではありますが、副業で hacomonoインターン の方々とは関わらせていただく予定なので、もしこの記事を読んでインターンに応募してくださる方がいればぜひ話しましょう!
株式会社hacomonoでは一緒に働く仲間を募集しています!
採用情報や採用ウィッシュリストも是非ご覧ください!